Luis Montes
Founder, Iceddev

First Song Played from Physical Media

1877 - Thomas Edison records on tin foil cylinder
"Mary Had a Little Lamb"
The Rise of Karaoke
- 1971 - Kobe, Japan
- Daisuke Inoue invents karaoke ("empty orchestra")
- 1980s
- Spreads globally; karaoke boxes become cultural phenomenon
- 1990s
- Karaoke bars boom in US and Europe...

CD+G
A star is born
What is CD+G?
- CD+Graphics - Philips/Sony, 1986
- Standard audio CD with graphics embedded
- Backwards compatible with regular CD players
- Still extremely popular for karaoke today!
2.27% of each frame (1/33 bytes × 6/8 channels)
26.5 kbit/s

Less than this dial-up modem.

Why Does This Look Like an Atari?
| CD+G (1986) | Atari 2600 (1977) | |
|---|---|---|
| Resolution | 288 × 192 | 160 × 192 |
| Colors | 16 of 4,096 | 128 total |
| Rendering | 6×12 tiles | "Racing the beam" |
9 years newer, same visual era!
Why CD+G Won't Die
- Massive existing library (100,000+ songs)
- Professional publishers (Sound Choice, Sunfly, Chartbuster)
- Reasonable file sizes (MP3 ~4MB + CDG ~4MB)
- Every KJ has a CD+G collection
But it's 2026... can we do better?

And now the AI stuff

From Karaoke to DJing?
The DJ's Dream (Stems)
🥁 🎸 🎹 🎤
- DJs wanted to isolate parts of songs
- Vocals for mashups and remixes
- Drums for beat matching
- Previously: expensive studio stems or nothing
AI Source Separation
- 2015: Early neural network attempts
- 2019: Spleeter (Deezer) - first practical solution
- 2021: Demucs (Facebook/Meta)
- 2024+: Stem separation in DJ software
Demucs

Meta's Audio Source Separation
What is Demucs?
- Open source (MIT license)
- State-of-the-art source separation
- Runs on PyTorch
- Trained on huge dataset of music
Demucs in Action
$ python -m demucs song.wav
# Output: separated/htdemucs/song/
# vocals.wav
# drums.wav
# bass.wav
# other.wav
MP3 Files
MP4 Stems
🎬
The New Standard?
Stems Structure
song.stem.mp4
├── Track 0: Master mix - plays in normal players
├── Track 1: Drums
├── Track 2: Bass
├── Track 3: Other (keys, guitars, etc.)
├── Track 4: Vocals
└── Metadata: atoms
Why MP4 Stems for Karaoke?
- Real original audio - not MIDI recreation!
- Control vocal volume (or mute entirely)
- Practice with just vocals + one instrument
Demo Time!
But Wait...
We have the music separated.
What about the lyrics?
Whisper
OpenAI's Speech Recognition
What is Whisper?
- Open source speech recognition
- Trained on 680,000 hours of audio
- Multilingual (99 languages)
- Timestamp generation!
Whisper for Lyrics
{
"text": "Never gonna give you up",
"start": 43.52,
"end": 45.84
}
- Feed it the isolated vocals from Demucs
- Get word-level timestamps
- Embed directly into MP4 stems file
The Pipeline
┌───────────────┐ ┌─────────────┐ ┌─────────────┐
│ Any Song │ ──► │ Demucs │ ──► │ Whisper │
│ (mp3, flac, │ │ (Stems) │ │ (Lyrics) │
│ ogg, wav) │ │ │ │ │
└───────────────┘ └─────────────┘ └──────┬──────┘
│
▼
┌─────────────────────┐
│ MP4 Stems File │
│ with synced lyrics│
└─────────────────────┘
Whisper Challenges
- Not always perfect transcription
- Timing can be slightly off
- Struggles with some vocal styles
- Trained on speech, not music
... insurmountable?
LLMs

Clankers to the rescue!
LLMs for Lyrics
- Fix Whisper transcription errors
- Look up actual lyrics and align
- Keep lyric timing accurate
Example Corrections
Whisper: "Excuse me while I kiss this guy"
LLM: "Excuse me while I kiss the sky"
Whisper: "Hold me closer, Tony Danza"
LLM: "Hold me closer, tiny dancer"
Whisper: "I feel stupid and contagious"
LLM: "...actually that's correct" 🤷
Storing lyrics: MP4 Metadata
- Standard atoms - Artist, title, album, cover art
- stem atom - NI Stems metadata for DJ software
- kara atom - Synced lyrics for karaoke
One .stem.mp4 file works in Traktor, Mixxx, AND Loukai
Putting It All Together
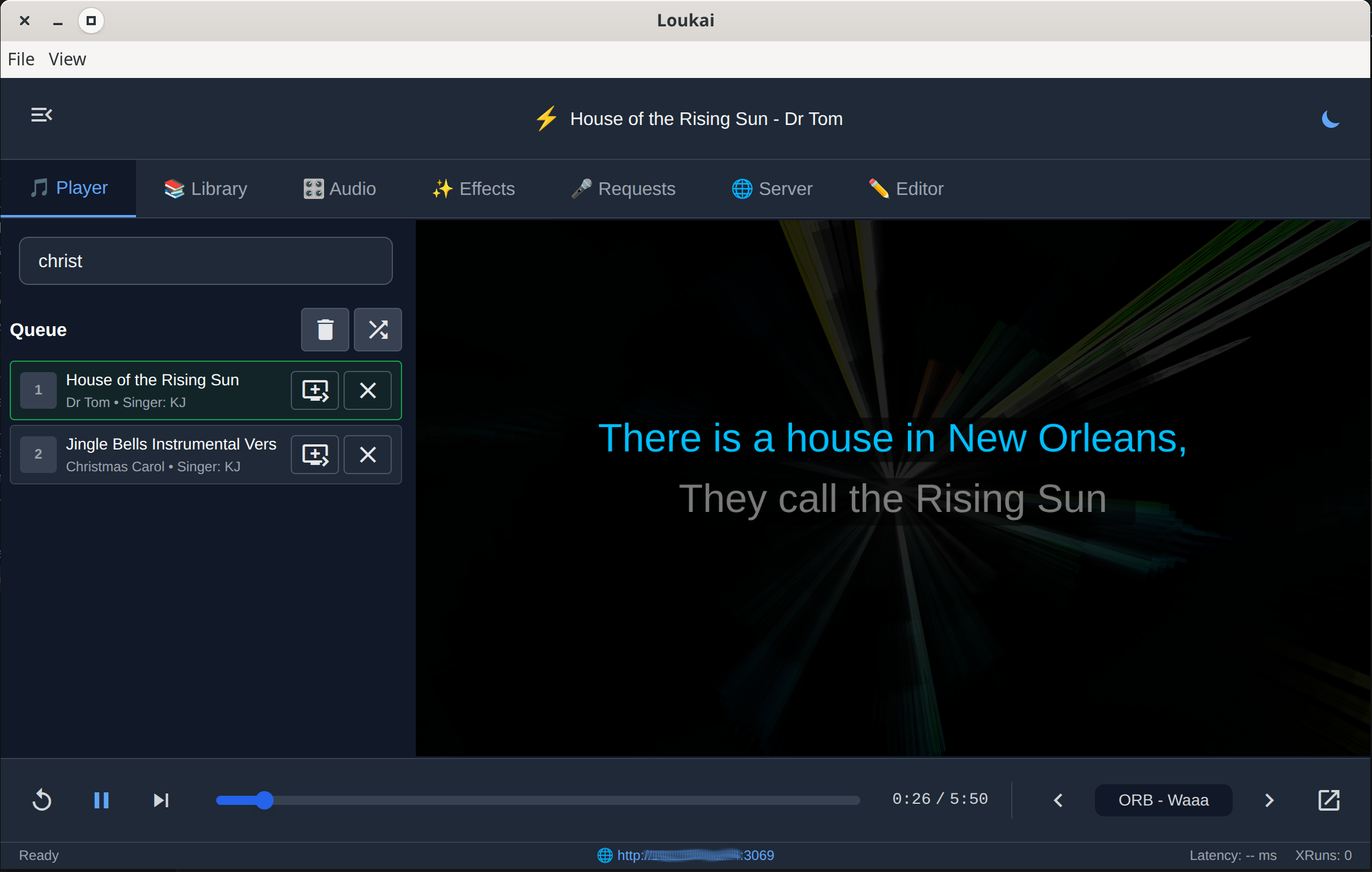
Open Source player
- MP4 stems karaoke with real-time mixing
- Also supports legacy CD+G format
- Audio-reactive visualizations
- Cross-platform (Linux, Windows, macOS)
Karaoke Creator / Editor
- Demucs - AI stem separation
- Whisper - AI lyrics transcription
- CREPE - Musical key detection
- LLM correction - Fix transcription errors
- Manual Editing - better timings, lyrics adjustments
any audio file → karaoke-ready .stem.mp4
Tech Stack
- Electron
- React
- Vite
- Tailwind CSS
- Butterchurn/WebGL
- Web Audio API
- Socket.IO
- WASM
- PyTorch
- ffmpeg
Demo Time!
Let's light this candle
Karaoke in 2026
- AI-generated stems from any song
- Automatic lyrics with timestamps
- Real-time pitch correction
- Vocal coaching
- Web GPU compute shaders?
.stem.mp4 is a worthy successor to CD+G !
Thank You
Luis Montes